作为一名中国程序员,甚至只是一名普通用户,编码问题一直困扰着我们的生活。包括 txt 乱码、网页乱码、程序乱码都屡见不鲜,各种“烫烫烫”和“棍斤拷”,还有方块?和莫名繁体。
字符编码相关知识:
- 《刨根究底字符编码之五——简体汉字编码方案(GB2312、GBK等)以及全角、半角、CJK》
- 《刨根究底字符编码之六——简体汉字编码中区位码、国标码、机内码、外码、字形码的区别及关系》
- 《刨根究底字符编码之七——ANSI编码与代码页》
- 《刨根究底字符编码之十——Unicode字符集的字符编码方式》
常见乱码解决方案:
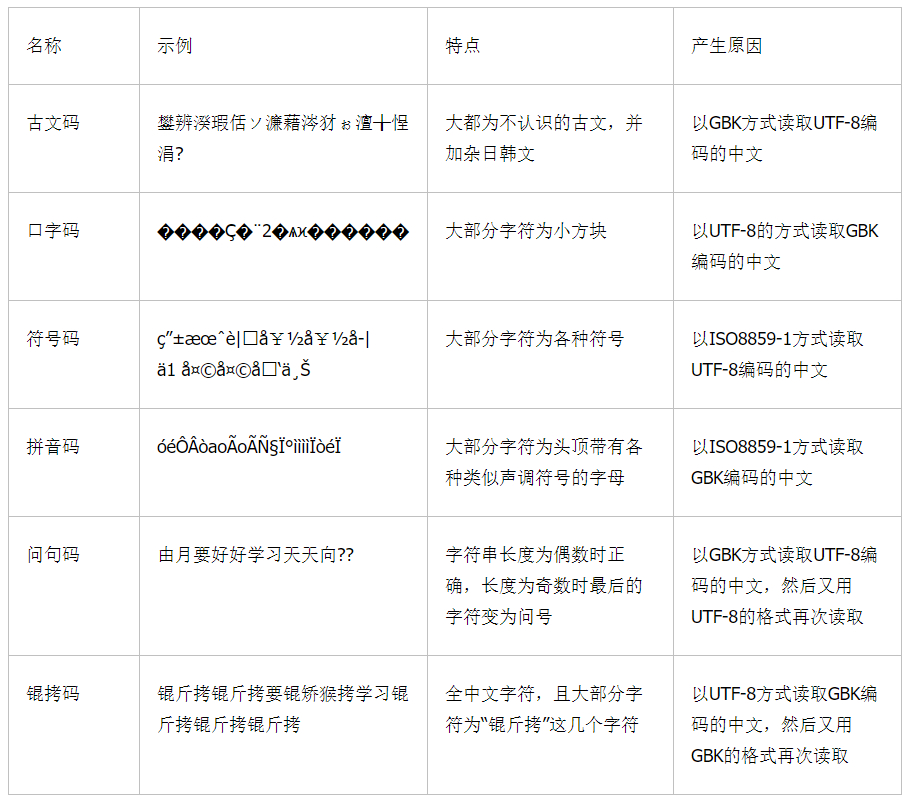
《常见乱码问题分析和总结》,这篇来自 IBM Developer,但现在中国站关了,只能从 web archive 看到了。

作者这次在调优文件协议解析模块时略有深入了解了相关知识,在此也有些吐槽。
该文件协议规定使用了如下数据规范标准。这些标准都是些常见的,但唯独不见 GBK,因为 GBK 名为汉字内码扩展规范,虽由国标委制定,但并没有列为推荐(GB/T),甚至在国标委系统中也找不到,在 GB18030 发布后应当寿终正寝,然而至今还在软件行业中依旧流行(实际是微软遗毒)。
GB 2312-1980 信息交换用汉字编码字符集 基本集
GB 18030-2005 信息技术 信息交换用汉字编码字符集 基本集的扩充
GB/T 1988-1998 信息技术 信息交换用七位编码字符集
GB/T 12406-2008 表示货币和资金的代码
GB/T 2260-2007中华人民共和国行政区划代码
ISO 3166 国家和地区代码表
作者在调优文件解析时发现 .net 中 GBKEncoding.GetString 能比 GB18030Encoding.GetString 快近一倍,同时 GB18030Encoding.GetChars 也比 GB18030Encoding.GetString 快。这是一个比较难以理解的现象,虽然 GBK 是2字节编码,GB18030 是4字节编码,但我的原始文本中应该是不含有4字节区的字符。
.net 当前内部字符串底层使用 char[] 实现,1个char是2个字节,实际编码是Unicode(UTF-16 LE),微软这样的这套设计现在感觉就有些落后,2字节顶多表示65536个字符,超过这个范围只能用代理对的方式实现,但现在unicode委员会依旧每年在不断的加字符(虽然主要是一些 emoji 表情)。不知道将来这个会不会进行修改,也许还会类似于 Windows Api 那样产生 _A 和 _W 这样2种 api。对照其他家语言的实现,go 和 rust 都使用 UTF-8 存储字符串,但这又带来了一些其他的问题(。
阅读源码 GB18030Encoding.cs 后,发现微软对这块转换的实现相当扭曲。其中2字节部分直接使用 CodePage cp936,cp936 可以视作等价于 GBK,之后4字节部分因为空间不连续的问题(0x81-0xFE,0x30-0x39,0x81-0xFE,0x30-0x39),则使用一个特殊算法通过区块映射的方式进行转换。
又阅读了 Unicode 委员会 ICU 项目里的 CharsetRecog_gb_18030.java、CharsetMBCS.java,ICU项目把 GB18030 映射到14个连续区块上了,看上去比微软映射无数个区块更高效(短)一点。
这2个实现,作者都看得脑壳疼,虽然大致实现思路是看懂了,但具体的转换公式没理解。不过这不影响作者大力出奇迹,作者直接根据 ICU-data 初始化码表,类似于微软的实现,2字节部分一个65536数组,4字节部分则使用一个2097152数组,不使用区块映射。4字节压缩解压缩规则:
uint b0 = gb18030code >> 24 & 0xFF; uint b1 = gb18030code >> 16 & 0xFF; uint b2 = gb18030code >> 8 & 0xFF; uint b3 = gb18030code & 0xFF; uint newCode = ((b0 - 0x80) << 16) | ((b1 - 0x30) << 12) | ((b2 - 0x80) << 4) | (b3 - 0x30); uint c0 = (newCode >> 16) & 0xFF; uint c1 = (newCode >> 12) & 0xF; uint c2 = (newCode >> 4) & 0xFF; uint c3 = newCode & 0xF; uint originCode = ((c0 + 0x80) << 24) | ((c1 + 0x30) << 16) | ((c2 + 0x80) << 8) | (c3 + 0x30);
最后测试时,该实现 Decode 速度相较于原实现提升近一倍,略慢于 GBKEncoding.GetString。测试还发现,ICU-data 提供的码表并不完整,4字节部分,缺少其他国家的一些字符,还有几个 private 区的编码与 .net 实现的 GB18030Encoding不一致,大概是因为 .net 实现未将码表规则更新到 GB18030-2005,只实现了 GB18030-2000,也有可能是故意忽略了,毕竟这几个字符在前后2个版本中显示字符是一致的。